 Overview on MPA framework design
Overview on MPA framework designAbstract
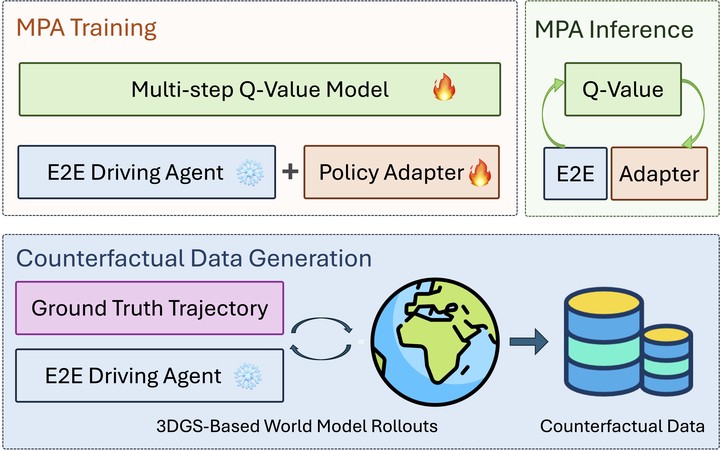
End-to-end (E2E) autonomous driving models have demonstrated strong performance in open-loop evaluations but often suffer from cascading errors and poor generalization in closed-loop settings. To address this gap, we propose Model-based Policy Adaptation (MPA), a general framework that enhances the robustness and safety of pretrained E2E driving agents during deployment. MPA first generates diverse counterfactual trajectories using a geometry-consistent simulation engine, exposing the agent to scenarios beyond the original dataset. Based on this generated data, MPA trains a diffusion-based policy adapter to refine the base policy’s predictions and a multi-step Q value model to evaluate long-term outcomes. At inference time, the adapter proposes multiple trajectory candidates, and the Q value model selects the one with the highest expected utility. Experiments on the nuScenes benchmark using a photorealistic closed-loop simulator demonstrate that MPA significantly improves performance across in-domain, out-of-domain, and safety-critical scenarios. We further investigate how the scale of counterfactual data and inference-time guidance strategies affect overall effectiveness.
Supplementary notes can be added here, including code and math.